As you read this, there are over 1.3 million active COVID-19 cases in the world. More than 70,000 people have succumbed to COVID-19.
It is becoming clear that much of the world does not, and will not, have the capacity to test enough people who show early symptoms of the COVID-19 infection. There are too many people with fever and cough at any given point of time in a country. Yet, detecting it early is an important means of preventing the transmission of COVID-19.
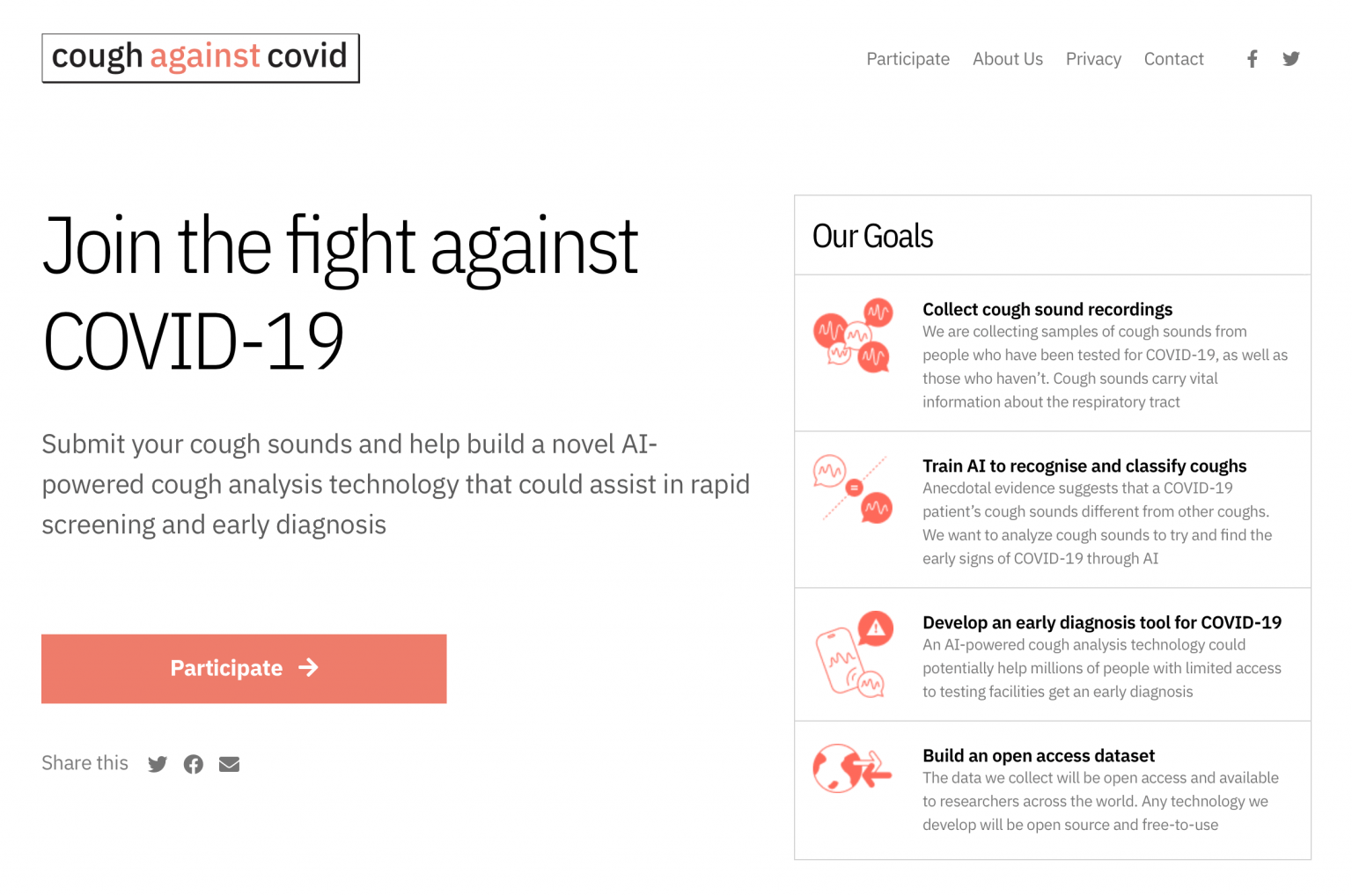
Today, we are announcing the launch of a global data-crowdsourcing and open-innovation initiative to try and build an Artificial Intelligence (AI) tool that uses cough sounds, symptoms, and other contextual information to screen for possible COVID-19 infection. Such a tool requires nothing more than a phone and can be used by people to self-screen. It will also help healthcare systems save limited tests for the most likely cases.
Our global data crowdsourcing campaign #Coughagainstcovid aims to collect samples of cough sounds from people who have been tested for COVID-19, as well as those who haven’t. Cough sounds carry vital information about the respiratory tract, and anecdotal evidence suggests that a COVID-19 patient’s cough sounds different from other coughs. The goal of #coughagainstcovid is to collect and analyze cough sounds to try and find the early signs of COVID-19 through AI.
Who are we? We are a not-for-profit, AI-for-social-good research institute. This initiative is supported by the Bill and Melinda Gates Foundation, and our collaborators include Stanford University. Collectively, we have world class capabilities in AI, medical technology, public health, and large-scale global deployment.
All data collected will be made freely available to researchers across the world (after anonymization) for open innovation. A global crisis calls for global collaboration.
We do not yet know if this is technically feasible. But we know it is not impossible. The only real way to know is to try.
A time like this calls for moonshots.
I have dedicated virtually all my professional life to large-scale breakthrough technologies for social good. This pandemic that has brought untold suffering to our world and it requires each of us to bring out the very best in ourselves.
Join us in humanity’s fight against this virus.