

Tuberculosis (TB) is a curable and preventable airborne disease that usually affects the lungs. One infected patient can spread the disease to 10-15 people within a year. In 2019, 2.6 million new cases and 440,000 TB-related deaths were reported in India, which continues to have the highest burden (26%) of all TB cases in the world.
Through its End TB Strategy, the WHO aims to end the global TB epidemic, with targets to reduce TB-related deaths by 95% and to cut new cases by 90% by 2035. Within the TB care cascade, we have identified specific areas for developing differentiated interventions.

Tuberculosis (TB) is a curable and preventable airborne disease that usually affects the lungs. One infected patient can spread the disease to 10-15 people within a year. In 2019, 2.6 million new cases and 440,000 TB-related deaths were reported in India, which continues to have the highest burden (26%) of all TB cases in the world.
Through its End TB Strategy, the WHO aims to end the global TB epidemic, with targets to reduce TB-related deaths by 95% and to cut new cases by 90% by 2035. With its ambitious National Strategic Plan (NSP) 2017-2025, the Government of India through NTEP plans to achieve a reduction in TB deaths by 90% and to reduce TB incidence by 80% by 2025, five years ahead of global timelines set for the country.
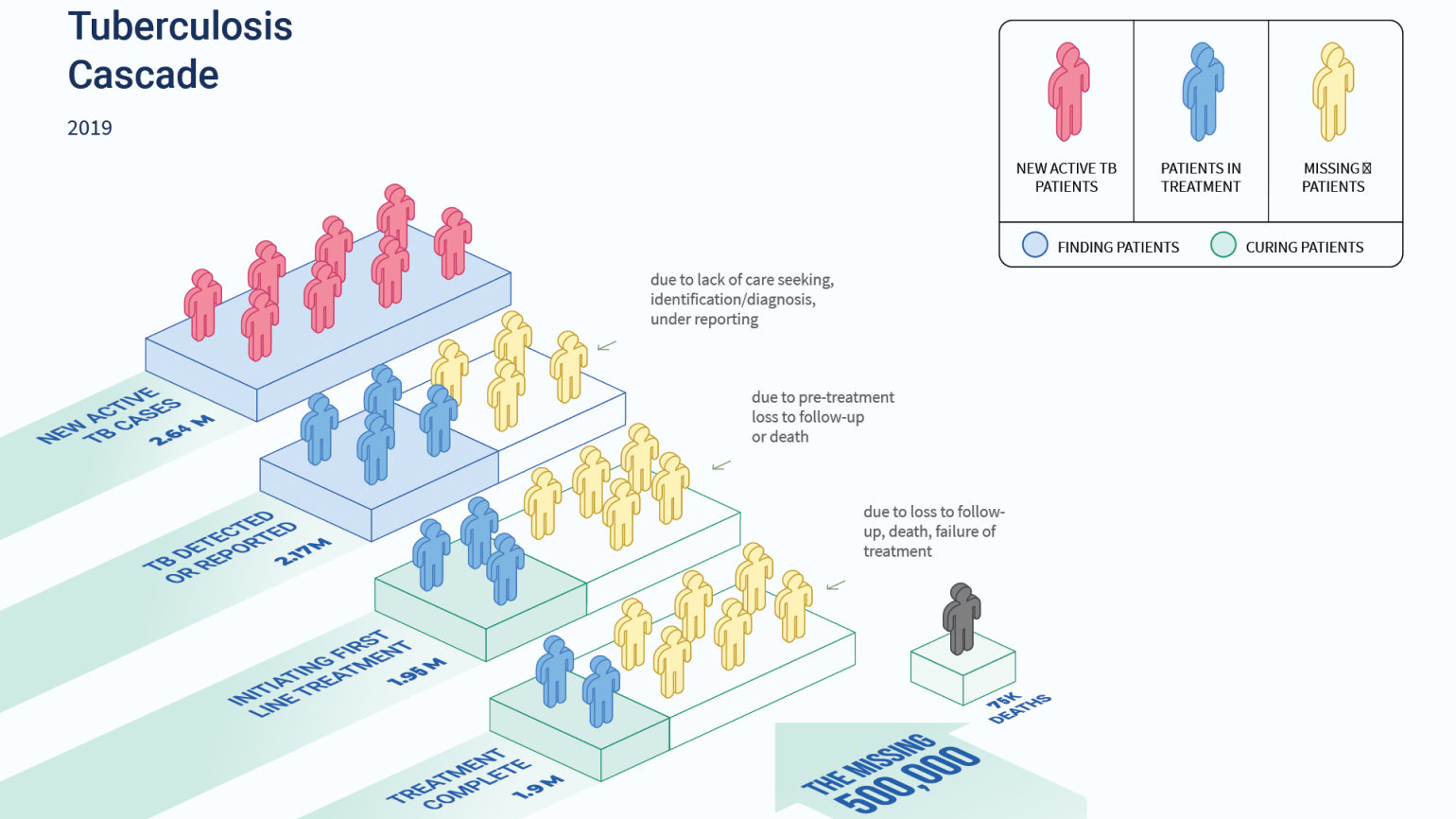
Identifying challenges at various stages in the TB care cascade. Source Global TB Report 2020; India TB Report 2020
Wadhwani AI is a close ally of the CTD, Ministry of Health & Welfare (MoHFW). We have also partnered with USAID to launch the TRACE-TB (Transformative Research and Artificial Intelligence Capacity for Elimination of TB and Responding to Infectious Diseases) programme, to support the NTEP.
Within the TB care cascade, we have identified specific areas for developing differentiated interventions. These include:
Interpretation of Line Probe Assay (LPA) strips
LPA is used to diagnose Drug Resistant TB cases (DR-TB). According to NTEP guidelines, all microbiologically confirmed pulmonary TB patients (an estimated 1 million) should be tested for drug sensitivity using LPA. At present, 400,000 tests are performed per year across 64 Culture and Drug Sensitivity Test (CDST) Labs. Errors in interpretation, in manual entry of results, and a prolonged turnaround time are causes for delays in initiation of TB treatment.
Risk for Loss to Follow-Up (LFU)
Treatment Success for TB patients is dependent on their adherence to the treatment regimen. An extreme form of non-adherence is Lost to follow up (LFU), defined as a TB patient whose treatment was interrupted for one or more consecutive month(s). Despite increased efforts, total diagnosed TB patients who were LFU along the TB care cascade in 2019 was over 4% of the total incidents. Early prediction is critical since these patients may be silent TB transmitters showing no symptoms and are at higher risk of development and amplification of DR-TB.
Inaccessibility of existing screening tools for TB
A large number of TB patients go unreported every year, and one major reason for this is the limited accessibility and availability of an inexpensive screening tool that is easy to use at the point of care. The screening tools that are currently used are expensive, and require special skills and laboratory setups. At a global level, a major priority for TB diagnostic
research is to have a rapid, non-invasive, and easy-to-use point-of-care tool for the screening of TB. Several studies suggest that AI-based solutions that use cough sounds of different intensities to classify people with certain respiratory diseases have performed well. Similar AI techniques can be implemented towards detecting tuberculosis at an early stage.
Triaging for emergency care
According to the Global TB Report 2021, the estimated mortality rate for all types of TB was 34–40 per 100,000 population in 2020. The India TB Report 2022 states that the mortality rate for all types of TB increased by 11% between 2019 and 2020. A few risk factors and indicators that have been identified as influencing TB incidence include undernourishment, diabetes, HIV infection, alcohol use disorders, and smoking. Reasons for mortality during treatment of TB have been reported to be due either to extensive TB and complications that come with it, or to certain comorbidities. The NTEP has developed a differentiated care model for TB patients to identify patients who require hospitalisation and reduce TB mortality.
TB Ultrasound
Chest X-ray is the leading screening tool for pulmonary TB. However, anywhere between 30-60% of patients do not get X-rays in spite of being given free coupons. There is a need for a portable, point-of-care screening system with automated readout.

© 2025 Wadhwani AI
ROLES AND RESPONSIBILITIES
An ML Engineer at Wadhwani AI will be responsible for building robust machine learning solutions to problems of societal importance; usually under the guidance of senior ML scientists, and in collaboration with dedicated software engineers. To our partners, a Wadhwani AI solution is generally a decision making tool that requires some piece of data to engage. It will be your responsibility to ensure that the information provided using that piece of data is sound. This not only requires robust learned models, but pipelines over which those models can be built, tweaked, tested, and monitored. The following subsections provide details from the perspective of solution design:
Early stage of proof of concept (PoC)
Late PoC
This is early to mid-stage of AI product development
Post PoC
Responsibilities during production deployment
We realize this list is broad and extensive. While the ideal candidate has some exposure to each of these topics, we also envision great candidates being experts at some subset. If either of those cases happens to be you, please apply.
DESIRED QUALIFICATIONS
Master’s degree or above in a STEM field. Several years of experience getting their hands dirty applying their craft.
Programming

ROLES AND RESPONSIBILITIES
As an ML Scientist at Wadhwani AI, you will be responsible for building robust machine learning solutions to problems of societal importance, usually under the guidance of senior ML scientists. You will participate in translating a problem in the social sector to a well-defined AI problem, in the development and execution of algorithms and solutions to the problem, in the successful and scaled deployment of the AI solution, and in defining appropriate metrics to evaluate the effectiveness of the deployed solution.
In order to apply machine learning for social good, you will need to understand user challenges and their context, curate and transform data, train and validate models, run simulations, and broadly derive insights from data. In doing so, you will work in cross-functional teams spanning ML modeling, engineering, product, and domain experts. You will also interface with social sector organizations as appropriate.
REQUIREMENTS
Associate ML scientists will have a strong academic background in a quantitative field (see below) at the Bachelor’s or Master’s level, with project experience in applied machine learning. They will possess demonstrable skills in coding, data mining and analysis, and building and implementing ML or statistical models. Where needed, they will have to learn and adapt to the requirements imposed by real-life, scaled deployments.
Candidates should have excellent communication skills and a willingness to adapt to the challenges of doing applied work for social good.
DESIRED QUALIFICATIONS


