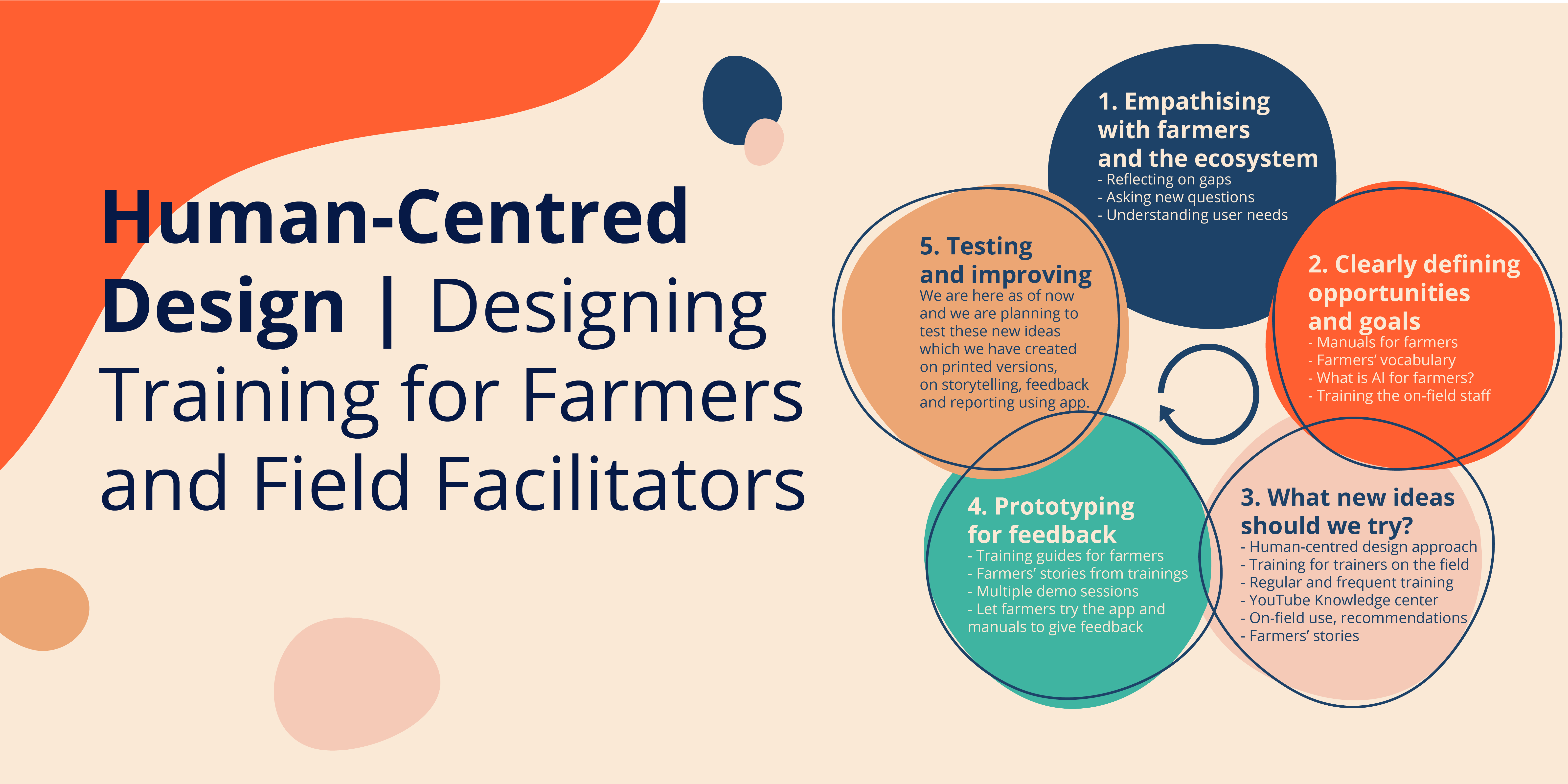
When you have teams that focus on channeling the vast power of Artificial Intelligence for social good, across domains such as maternal and child health, cotton farming, and tuberculosis, it is vital to have a framework that everyone can work within, no matter what their individual projects are. At Wadhwani AI, our expertise is spread across AI research, data science, engineering, design, products, and programs.
We’ve created a set of anchoring principles, if you will, that serve as our touchstone before we decide to embark on a project:
1. IS THIS A BIG PROBLEM?
At Wadhwani AI, we measure our success based on the impact we are able to catalyse, and keep the communities we are trying to help, at the core of our solutions. We aim to take on truly large problems that affect the developing world, and use our global lens to then create solutions that can be scaled and are applicable across the world.
2. DOES IT HAVE AN AI SOLUTION?
This is a crucial question. For example, when we decided to work on a program centred around tuberculosis, we had to examine all aspects of the issue. To start off, we examined how TB is diagnosed—one way is by analysing the patient’s sputum, but this is already automated and widely so. Image-recognition algorithms also exist that can count the number of bacteria. But where could Wadhwani AI play a role? A few weeks of research later, we had the answer: nearly as many as 50% of TB cases may go unreported and unknown, and we could help change this number.
3. WILL SOLVING THE AI PART MAKE ENOUGH OF A DIFFERENCE?
Earlier this year, Wadhwani AI became the official AI partner for India’s Central Tuberculosis Division. Now, we are creating technologies to address multiple challenges starting with case load estimation and prioritisation of TB patients for health workers.
4. WILL THE SOLUTION BE ACCEPTED BY STAKEHOLDERS?
In the case of our tuberculosis project, we know we can make a difference, and that we are an acceptable part of the system to the other stakeholders. This is not always the case, as we learnt when we considered the possibility of addressing clinical support decision systems for doctors in primary healthcare centres through AI. While we could have automated a lot of the routine diagnosis and treatment processes, doctors were not open to the idea at all. Their reason was that too much automation would make patients lose faith in the doctors and their expertise.
5. DOES THE DATA EXIST, OR CAN IT BE CREATED EASILY ENOUGH?
Understanding issues such as these, and getting our research and data right is only possible when we find the right partners. We find that the best way for us is to identify people and organisations who have been working in the field for decades. Their deep understanding of the communities and the problems are invaluable to us because data about issues that are of societal consequence does not always exist. AI systems function on data, so at Wadhwani AI, research and data collection are key.
6. ARE THERE PARTNER ORGANISATIONS WHO CAN CO-CREATE AND PILOT?
Our partners in our Maternal and Child Health project are a good example of this. We could plug into the system, and create a mechanism that works within the existing apps. Plus, this is also a domain that is of global importance and consequence, so our work can be implemented internationally.
7. ARE THERE EXISTING PROGRAMS AND PATHWAYS TO SCALE?
Our ideal project is one in which we don’t have to create an app, and we don’t get stuck in the land of pilots. We aim to scale up as quickly as possible and take the project from an Indian context to a global one.
As a team we use these seven key questions to identify domains in which we can help the underserved billions by creating solutions that impact their lives in a meaningful way.