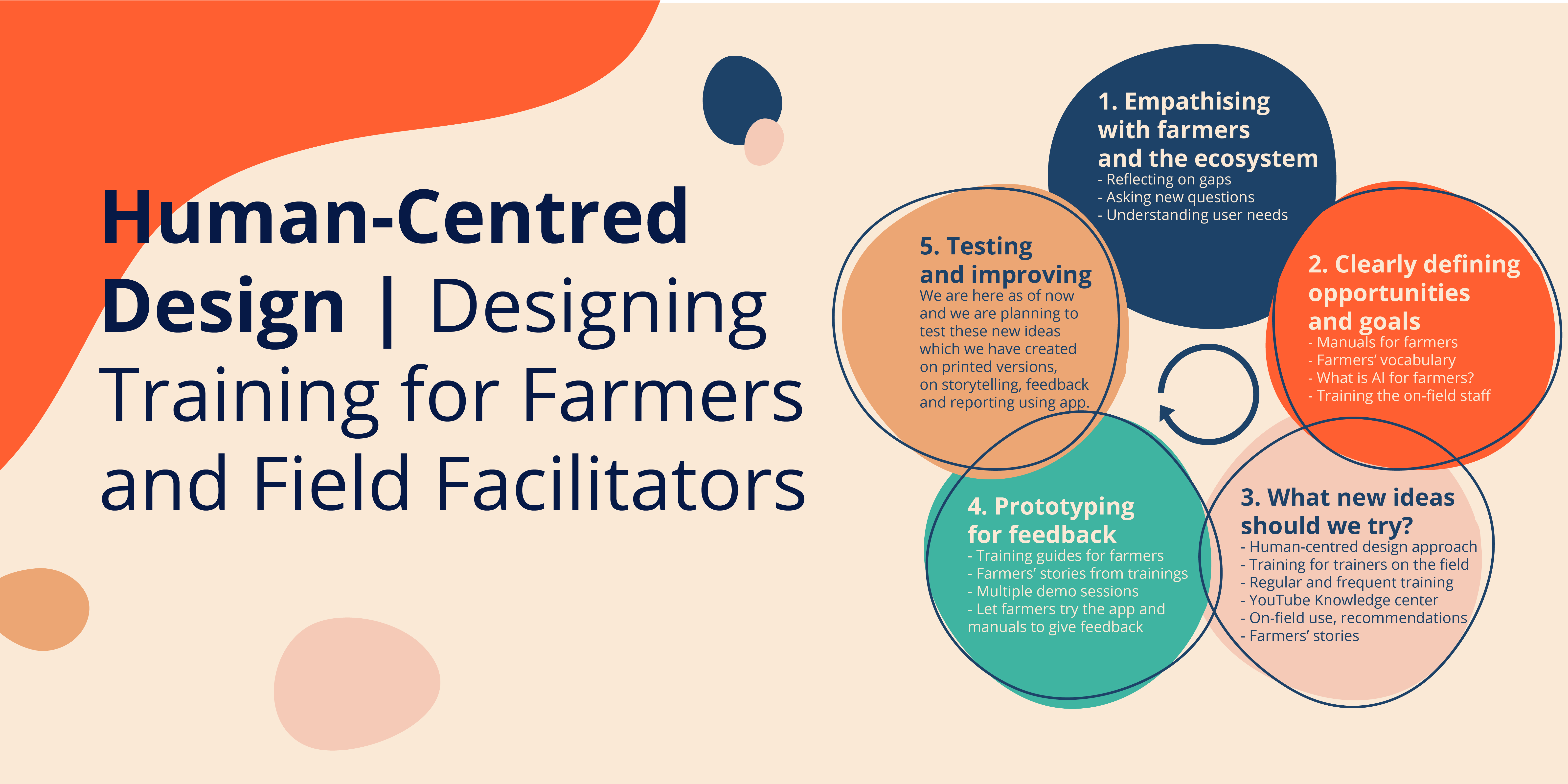
We work with cotton farmers. Not only is cotton one of the biggest cash crops in the world it is also plagued with its own risks. Over the past few years, pests ravage farms, destroying, at times, over 50% of the total yield. Farmers are at a loss. Traditional methods have stopped being as effective. AI could be an answer. But there are challenges.
First, let’s take a quick look at the headline numbers around India.
- India is a land where 1.4 billion people coexist.
- 1 billion handsets.
- But just 450 million smartphones.
- It doesn’t mean that 450 million people have smartphones, it means people have multiple handsets.
Among smartphones, Apple holds just 2.6% of India’s smartphone market share. What does that tell us? There are a handful of premium phone users in India. These users aren’t in small-town India.
Almost 50% of phones cost less than Rs 10,000 (~$130). Let’s take a look at our user. Our typical user is male, around 35 years old. Uses WhatsApp to forward messages and YouTube to watch videos when he can. That’s his interaction with the internet. He is not digitally literate. So, there are three major challenges.
- Limited computation capacity
- Data connectivity
- Digitally semi-literate user
Our solution uses a simple smartphone and pest traps. The biggest problem facing cotton farmers across the world is the need to know how much pesticide is needed to ward off attacks and if it is too late to spray in the first place. Our solution asks the farmer to take a picture of a pest trap and get actionable advice.
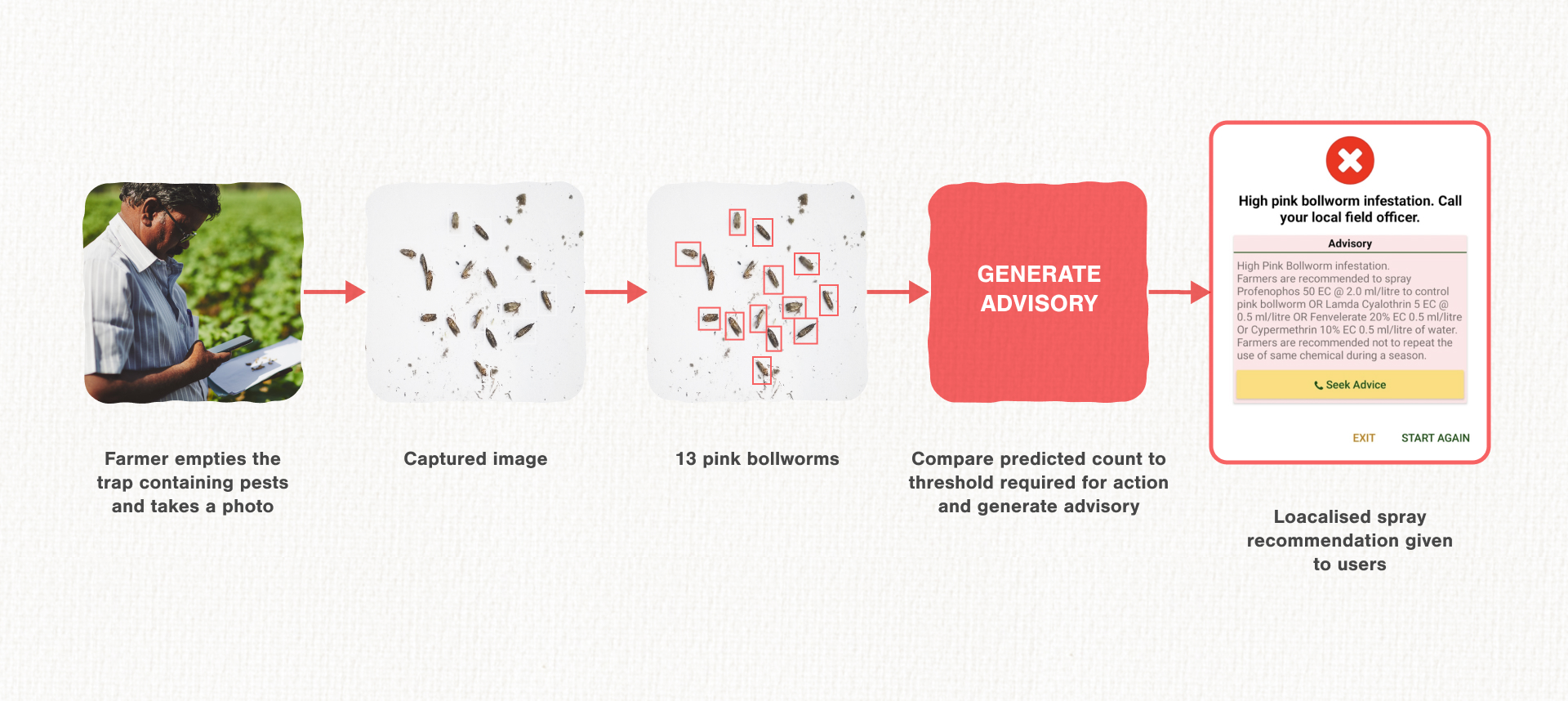
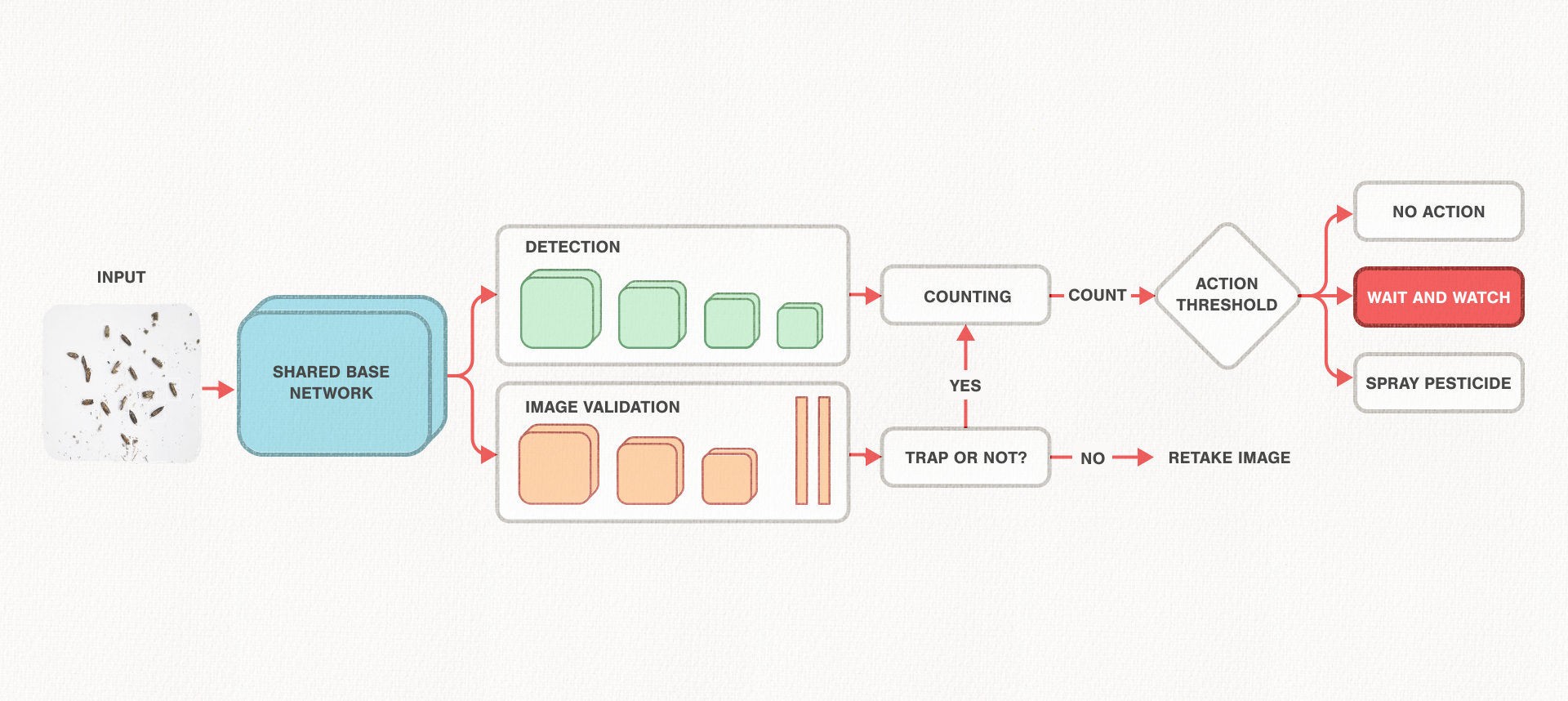
What happens behind the scenes? Using features generated from a convolutional neural network, our system first determines whether the image is valid. If it is, those features are then used to detect and count the number of pests that are present. Using this count and with the help of guidelines set by entomologists, the system recommends an action to the farmer—to spray or not to spray pesticide. We train our models on a data set of around 4,000 images we collected in collaboration with smallholder farmers all over the country.
But our model size was almost 250MB and since the initial deployment was web-based, it required a steady internet connection on the user’s side. During our field experiments, we realized that network connectivity became a major bottleneck to great user experience. One way to address this problem is by doing all the computation offline. However, we cannot simply store a 250MB large model on even high-end phones There needed to be a solution. If you need context for the problem we faced, this from Apollo 13 should set the mood.
Now that you have context. Let’s get to some brass tacks.
Begin the begin
Compute resources are largely constrained by two factors. The first is mobile network coverage. Many smallholder farms in India are located in areas that are poorly connected. And these conditions hamper the user experience. The second constraint comes from integrating products into partner interfaces. Solutions need to be mindful of size and quality of service guarantees. Evidence of these challenges was seen during our data collection effort.
Our solution was placed on 17 phones that belonged to a mix of extension workers and farmers. The experiment ran for 60 days across 25 farms, providing 89 recommendations based on pink bollworm catch. The average per image upload time was approximately 38.5 seconds (95% CI [33.6, 43.3]), which represented 48% of task completion time. For users, this was especially problematic in cases where they had network connectivity in a location different from where they took the photo. In these conditions, the users had to travel to an area with connectivity to complete the task. This inconvenience was exacerbated in cases where a retake was required: a farmer would take a photo in the field, walk to an area with connectivity to perform the upload, then be forced to walk back into the field for a retake upon learning that the image was invalid. In addition to the log analysis, qualitative follow-ups showed that these upload times would be a barrier to adoption.
Goal
We first established a target model size by examining the size of our partner’s app and understanding the general sizes of other agri-tech apps. General sizes were found to be between 15 and 20 MB. From there, we decided a model size of 5MB would be a good target. Getting to this size was essentially an exercise in model compression.
Stumble 1
The easy thing to do would be to tell you what we finally did. We will, but in a bit. But every wrong solution is a path to the right one. So let’s start with how each step led us to our ultimate goal.
As we already mentioned before, our multi-task learning model consists of a shared base network that computes features from the given image and the features, in turn, feed into the detection and validation head. It is important to note that the base network takes up almost 80% of the compute time in SSD, the single-stage object detection model from which our multi-task network was eventually developed. So, as a first step, we tried to use a smaller base network. MobileNets has been shown to effectively reduce the model size by using Depthwise Separable convolutions instead of regular convolutions throughout the network, while still maintaining a reasonable accuracy for classification tasks. We tried using both MobileNet v1 and v2 instead of our base network, which was a VGGNet. Even though the accuracy drop was not huge, we realized that we are still very far from our goal of achieving a 5MB model, and the subsequent accuracy drops to reach there by following this approach would accumulate, making the solution infeasible.
The answer
We adopted a version of filter-level pruning known as iterative pruning, specifically using the technique mentioned here. The idea is to iteratively prune a fixed number of filters followed by training the pruned model until we achieve our desired memory size.
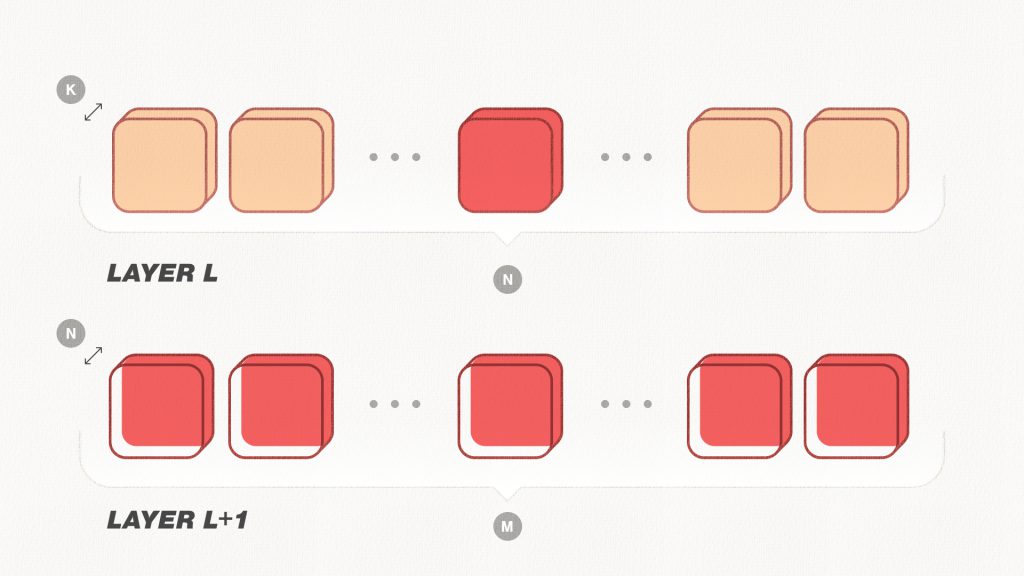
The figure above shows how one filter gets pruned as described in this paper. Let’s look at two consecutive layers, L and L+1. The number of input channels for layer L is K and the number of output channels is N. Since the output of layer L serves as the input for layer L+1, the number of input channels for layer L+1 is also N, while the number of output channels here is M. Pruning the filter at index i from layer L would reduce the number of output channels of layer L, and hence, the number of input channels in layer L+1, by one. Thus, for pruning the chosen filter, we also need to update all the layers which branch out from layer L.
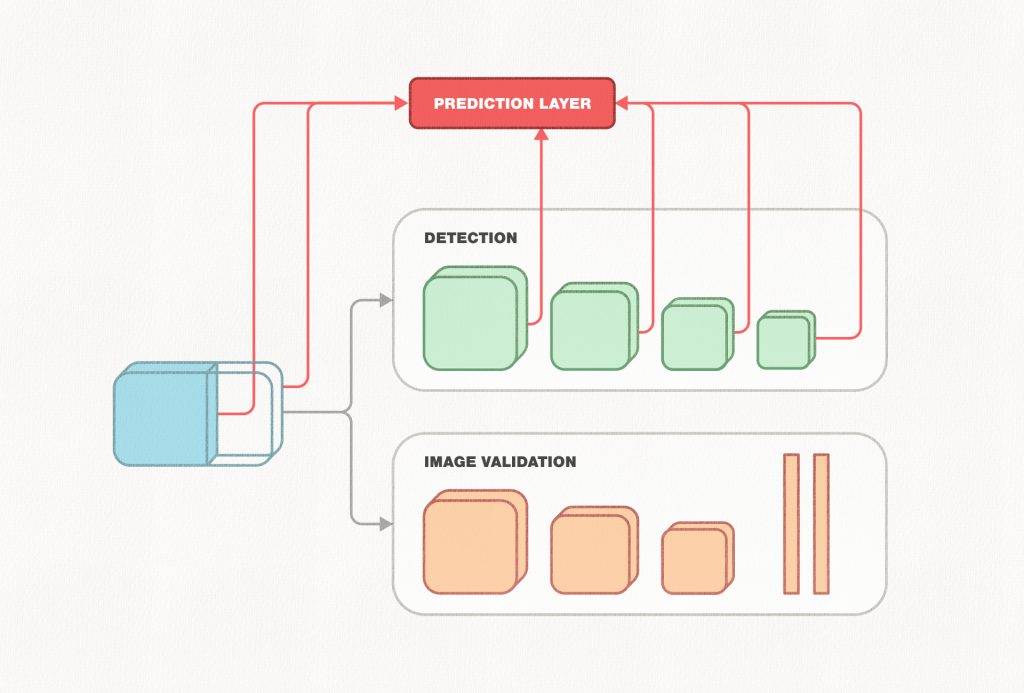
There are always speed bumps
We adapted this technique for our model, which consisted of both a detection head and a classification head. This had its own challenges. If you look at the figure above, there are several branches that snake through the network. So, if say, a layer in the base network is pruned, the correspondent branches in the box-predicting layer and the values associated with it also needs to be pruned. Furthermore, if the layer being pruned is the last layer of the shared base network, which is not only a box predicting layer, but also the input for both the detection and image validation branches, the corresponding values from the first layer of both the heads have to be pruned accordingly.
It is a time-consuming task. We pruned 1,024 filters in each iteration, followed by 30 epochs of training until ~80% of the total number of filters in the original model were pruned. The weights of the final pruned model were saved in half-precision to further reduce the memory footprint on disk.
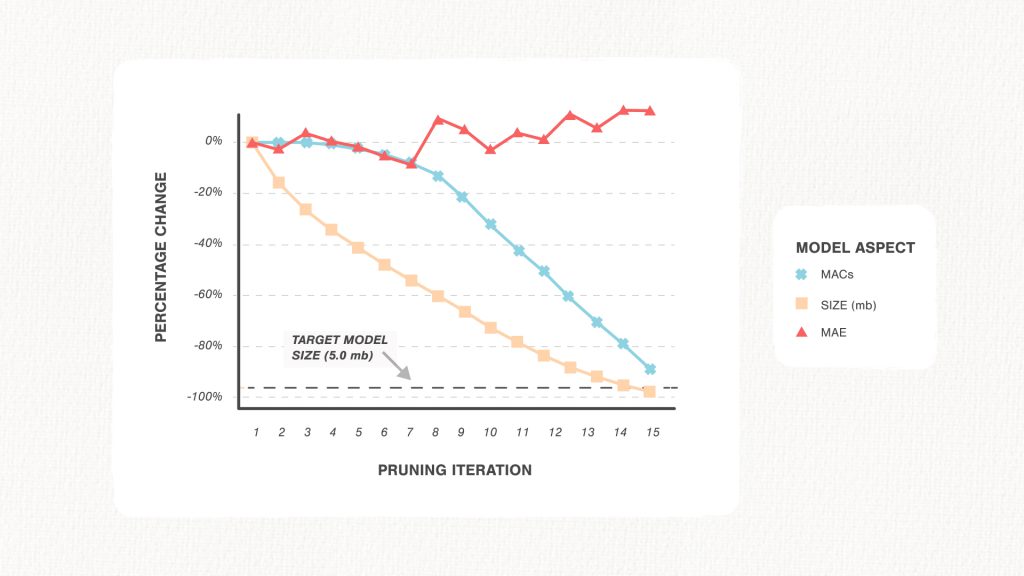
The figure above figure details the outcome of this effort. Iteration zero represents the original, unmodified model that we begin with; its size after quantization was approximately 132MB. Subsequent iterations come after a round of pruning. The required model size of 5MB was reached after 15 iterations, where the mean absolute error between the predicted and true counts increased only from 0.91 to 1.02. In addition to a reduction in size, the compressed model was also less compute-intensive, as seen from the drop in multiply-accumulate operations (MACs).
Lessons we learned
Our typical user is probably more sensitive to small changes in experience than the average smartphone user across the world. The solutions need to be not only easy to use but also lightweight and have the ability to work offline. This was a core principle and it drove our approach, which has been to do as much computation offline as possible. Having offline inference allows better management of data privacy as the solution scales because there is finer control on what user data leaves the phone. We managed to do that by compressing our model to the smallest size with minimum loss in performance. It is important to quantify this need early on, to set the right expectations with the respective stakeholders in terms of latency, model size and accuracy.
We wrote a paper on our entire journey, our learnings, and the technology. It was accepted at KDD 2020 in the Applied Data Science track. You can read it here. There is a video as well.
Rameshwar Bhaskaran and Siddharth Bhatia were interns assigned to this project.