

As of publishing this post, over 130,000 people have died because of Covid19. It is a disturbing number. The virus has overwhelmed health services and dominated headlines. But tuberculosis (TB), according to news reports, claimed 80,000 lives in 2019 and continues to be one of India’s biggest public health challenges.
Earlier, the government of India announced an ambitious target to end TB by 2025. There was a reason for singling out this infection. About a third of global deaths due to TB are in India. According to reports, about 2.4 million people with TB were reported in India in 2019 and 2.64 million were estimated to have the disease in 2019. TB is a challenging disease to fight against. Physicians say that the bacterium that causes TB can stay dormant in a person for an indefinite period and can activate at any time, which can cause the patient to manifest symptoms.
But despite this, most strains of TB are curable. A rigorous six-month regimen can treat the infection. But patients either aren’t diagnosed or don’t follow through on treatment. This makes the fight even harder.
How India handles TB
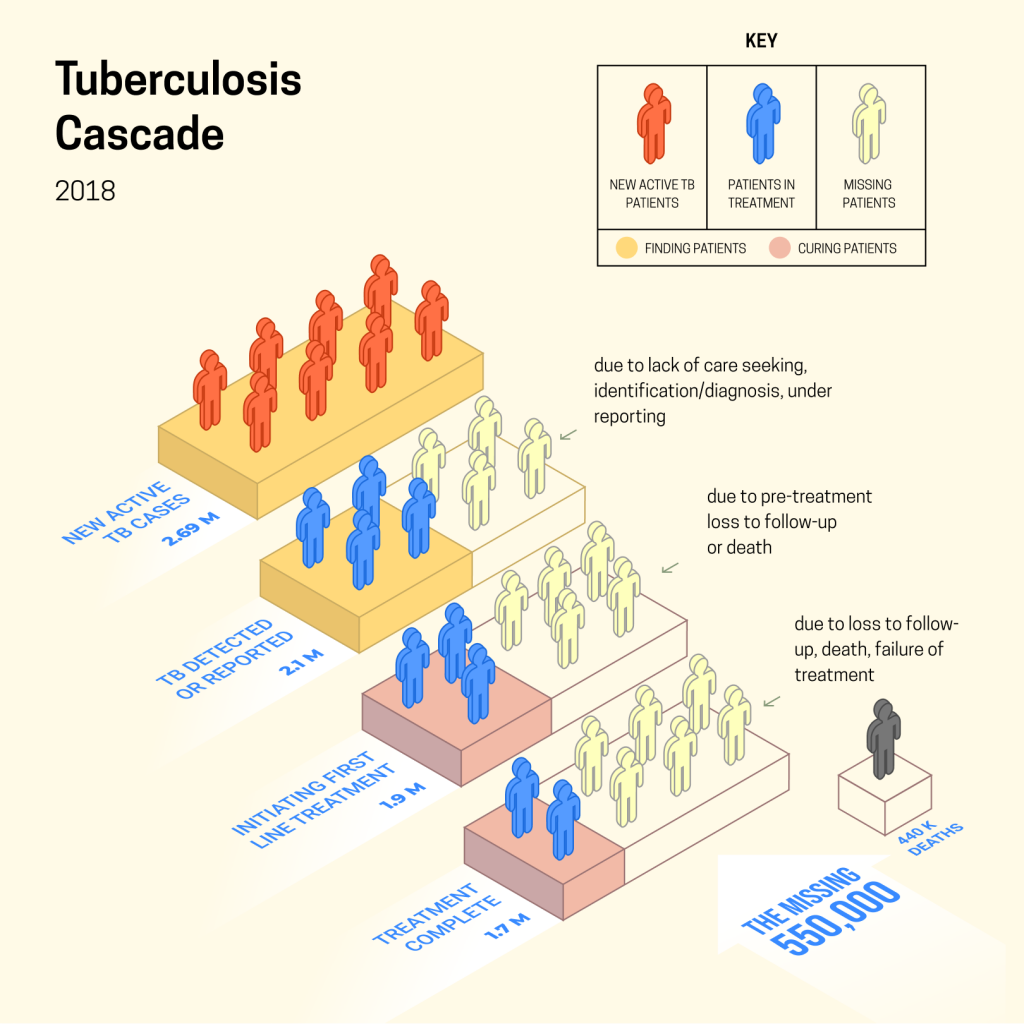
India has a multipronged strategy when it comes to handling TB. Health workers canvas at-risk areas and speak to people in those locations. Because TB has non-specific indolent early symptoms, there are no obvious tell-tale signs. Patients are encouraged to visit health facilities if they show symptoms. There, healthcare workers or doctors direct them to get lab tests. This is where leakage first begins, some patients never visit the centre or those who visit are not directed to get tests.
Those who do, and are diagnosed by subsequent lab tests, are registered on a national database, where their treatment is tracked. This is where the second challenge emerges. Some patients are misdiagnosed and miss out on much-needed care. Those who are accurately diagnosed, are assigned a doctor.
As of 2018, in India, over 50% of the estimated 2.64 million people who have TB and walk into clinics seeking care do not go through the public healthcare system. This means the accuracy of diagnosis, estimation of caseload or adherence to treatment is unknown. This is another point where patients can’t be tracked for care. According to research by public health professionals, TB treatment in the private sector is fraught with challenges. In private care, the physicians may not follow standard protocol and a lack of structure can cause an absence of supervision, which leads to patients stopping treatment prematurely.
Those patients who take the public healthcare system are prescribed medication. The government has enabled a call centre service that patients can use to discuss treatment and ask questions to healthcare professionals. During treatment, India loses another clutch of patients. In public health, this is called, “loss to follow up” or LFU. This increases the risk of the patient developing drug resistance and spreading the infection to others.
The role AI can play
Artificial Intelligence (AI) can potentially play a role through the cascade of care. One of the primary challenges in the existing system is the identification of hotspots. Most healthcare workers use obvious income and population density markers to find probable patients. Researchers could also create an AI model, which will be able to identify potential patient locations depending on markers beyond just the two currently used, hence making it easy to find patients in non-obvious locations as well.
Wadhwani AI has also developed a model, where a patient can be triaged for being at risk of having the coronavirus. The argument, hence, can be made that a similar tool can be used to triage TB patients without the need for issuing X-ray vouchers.
Once identified, the patient can be tracked and according to certain behavioural patterns and contextual data, researchers believe that an AI model can predict who is likely to be lost to follow up.




