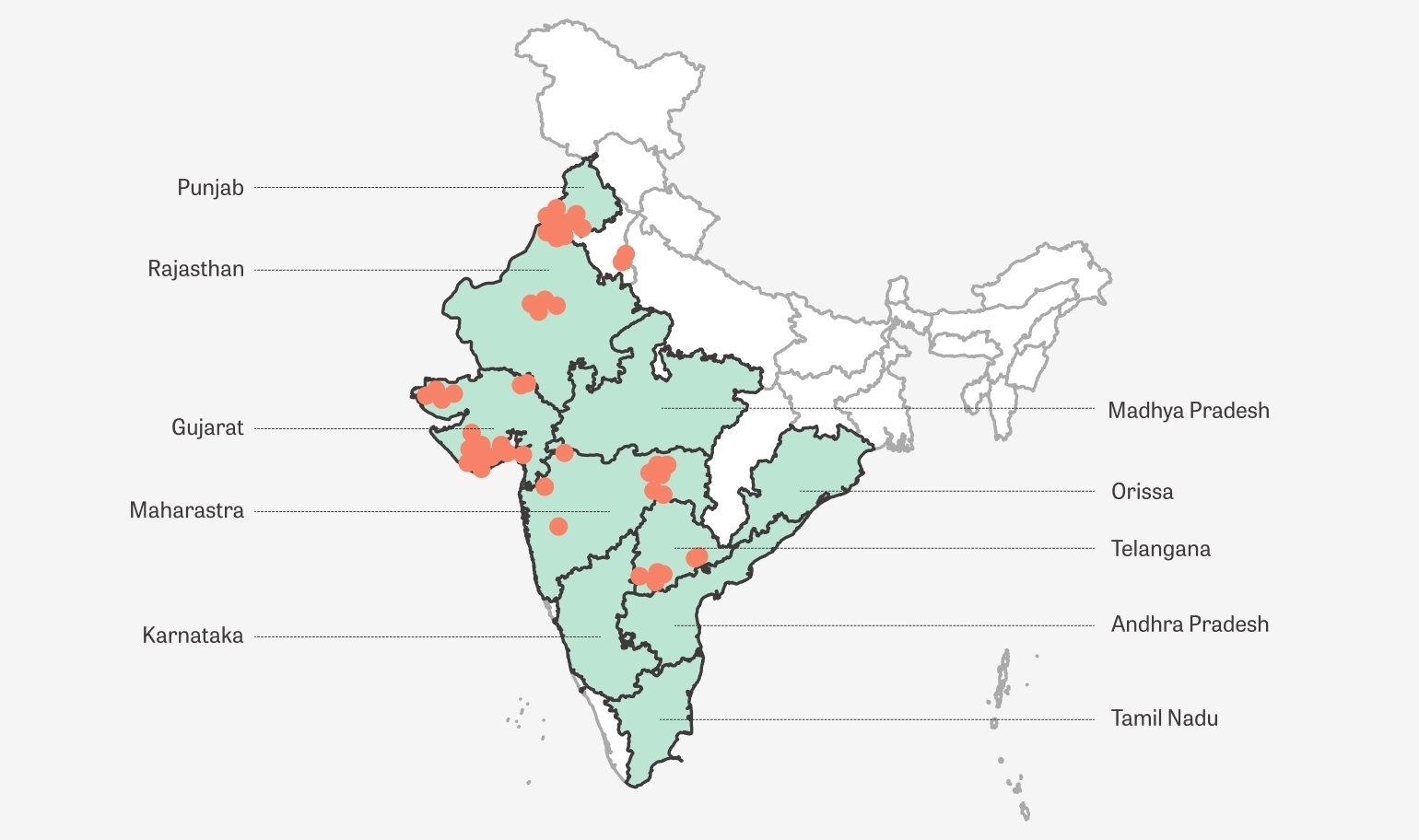
In Kharif 2021 (June to December) season, a detailed impact assessment has been planned across 65 districts in India with our scaling partners. It will include a sample from the roughly 10,000 Lead farmers who are part of this season’s deployment, our largest to date.
Primary users of the CottonAce app – lead farmers – are selected for the lead role they play in guiding fellow (cascade) farmers in their respective communities. There are between 50,000-100,000 lead farmers growing cotton in India, who are trained by farmer welfare programs to manage local pest infestations, including with the help of CottonAce. On average, a single lead farmer will disseminate the app advisory to 10 cascade farmers, thereby extending the overall reach of the solution.