There is research that shows that a cough contains a lot of information. We wanted to prove that this cough has indicators that would help us screen COVID-19 patients. And we did. I urge you to read our blog that explains how Cough against COVID can increase testing by 43% while keeping the number of lab-based tests constant.
To achieve this, the research team had asked us for a wide range of coughs, a dataset, which represents the width of India. To the best of our knowledge, we have collected the largest cough sample dataset for COVID-19. The dataset comprises 40,000 sounds from more than 7,000 individuals. We were happy, mind you. But now that the dust has settled on our five-month-long sprint, it isn’t the size of the dataset but the processes that we put in place, the best practices we followed, and the support we got from our partners through the process that gives us pride.
Let’s take you back a few months when we decided to start facility-based data collection. There were ground realities we had to consider before we chose our facilities. At the time, the virus was locked in the big metros such as Mumbai and Delhi. It was rearing its head in states like Tamil Nadu as well. There were cases outside these places but the healthcare systems did not seem to be overwhelmed. Our first pick to set up our cough collection facility was in Bihar. There were two reasons we chose this site.
- Disease prevalence. We wanted to go to a low disease prevalence area. When the healthcare systems are overwhelmed, hospital administrators and doctors have different priorities.
- We found the right partners in the Norway India Partnership Initiative (NIPI) and Doctors for You (DFY). We have been working with NIPI on another project and the partnership, in this case, seemed organic.
Since India was under lockdown, our program team couldn’t travel to set up processes and do in-person meetings. We leaned on partners such as DFY, who had feet on the ground, to help us get institutional ethics committee approval and on-board field staff to carry out research. NIPI, due to its unique nature, helped us get statewide administrative approval quickly. They facilitated one-on-one meetings with the senior-most public health officials so we could explain our research to them. Once we got the go-ahead to collect cough samples, we initiated activities at SK Medical College, Muzaffarpur and Nalanda Medical College, Patna. Now was the time to set up our processes, which would collect high-quality data and protect our on-ground research coordinators. It was an iterative process but we finally came up with standard operating procedures.
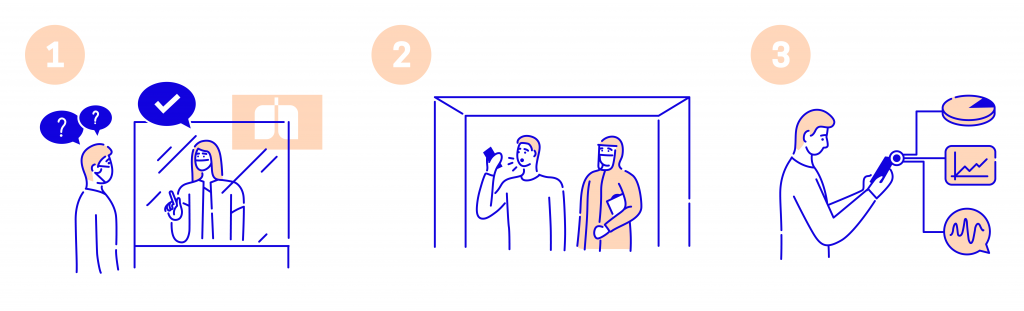
1. The patient walks through the door and is screened by the hospital staff. If she is determined to be eligible for the RT-PCR test, she is informed of our research. On receiving consent, she is led to a recording room. All her demographic and contextual information is recorded on an app. Let’s call it app #1.
2. In the recording room, a PPE-clad research assistant records cough and speech samples on a smartphone. These samples are recorded on another app. Let’s call it app #2. This smartphone doesn’t leave this room.
3. The patient is then led to another chamber for a lab-based test. Once the results of the lab test of the patient are generated, they are recorded in app #3. The information in all three apps is now merged to get one full dataset.
This SOP helped us formalise a process, which was replicated (with small contextual variations) in Odisha, Rajasthan, and Maharashtra.
We picked each of these states for various reasons and, honestly we were not shy of being opportunistic either. We wanted to conduct our research at scale and at pace. For example, in Mumbai, once we got regulatory approvals, we partnered with Doctors For You, which mobilised healthcare workers during times of crisis. Their ground staff started assisting us in collecting data. We also partnered with Radical Health, a technology firm working with MCGM for comorbidity screening of high-risk individuals.
In Rajasthan, we partnered with AIIMS Jodhpur because it is a unique hospital. In the early days of the pandemic, Indians returning from overseas, with possible COVID-19 exposure, were being treated there. It gave us a large collection of patients at a single location. Partnership with NIPI opened up all major testing sites in the state of Odisha.
This gave us a wide variety of sounds from different corners of India.
While data collection procedures were in place, we also had to set up research coordinator procedures. The first step was to hire the right people. For us, step one was to find candidates who lived in the same city, had worked in hospital settings and had participated in data collection studies. It was a niche demand. But we found them. Once they were introduced to our data collection SOP, we had to create systems which would help them stay healthy.
Since we couldn’t send them back home, we found hotels, hostels and apartments where these volunteers could be housed. We spoke to the hospitals so that they were treated as staff and allowed to access hospital canteens. We made sure they had adequate protective gear such as masks and PPE. We even taught them how to wear, remove and dispose of these masks.
Amidst lockdown, we organised the entire supply chain to provide necessary logistics to them. In situations where we couldn’t, our partners helped us provide them with kits from the hospital. Along with the prevalent infection prevention guidelines, we recognised that prolonged exposure to the COVID-19 patients may put them in danger of infection, so we put in place short six-hour shifts. In some locations, we would ask them to work in two-week sprints. So essentially, they would work for two weeks and have a cooling-off period of two weeks. We bought our coordinators insurance, both health and term, in case the dangers of the job got to them. At the peak of our exercise, we had 20+ dedicated coordinators apart from the active on-field staff of the partner organisations.
They are the real heroes. Recording coughs, talking to people and giving us feedback on how the app was functioning. Their feedback helped us simplify the app and sharpen our processes to a level that it could be explained in a short demonstration session to any new coordinators who joined the team.
Essentially, what we did can now be replicated by anyone across the world. My only advise: find the right partners. We were lucky enough to find the right ones who would help us fill in the gaps when needed.
I still remember our first week with great pride especially, on the very first day, when we had data from 20 patients recorded in a single day, We knew back then that we were building our dataset. One cough at a time.