Numbers in medicine hold great importance. Especially when it comes to TB. India carries the world’s largest burden of drug-resistant TB. Global TB reports suggest that there are 124,000 MDR-TB cases annually. Before you move forward, it is important to understand how India handles this TB pandemic. This post is good to get the conversation started.
These numbers have been bothering lawmakers and healthcare professionals across the world. The problem can get worse if the patient isn’t diagnosed on time and starts transmitting it to others. When India’s war against TB started, it would take up to three months to accurately diagnose a patient. In 2008, the healthcare world got a reprieve when Line Probe Assay (LPA) was introduced to diagnose drug resistance among TB patients. This is a rapid molecular diagnostic technique which brought down the turnaround time from three months to just about five days.
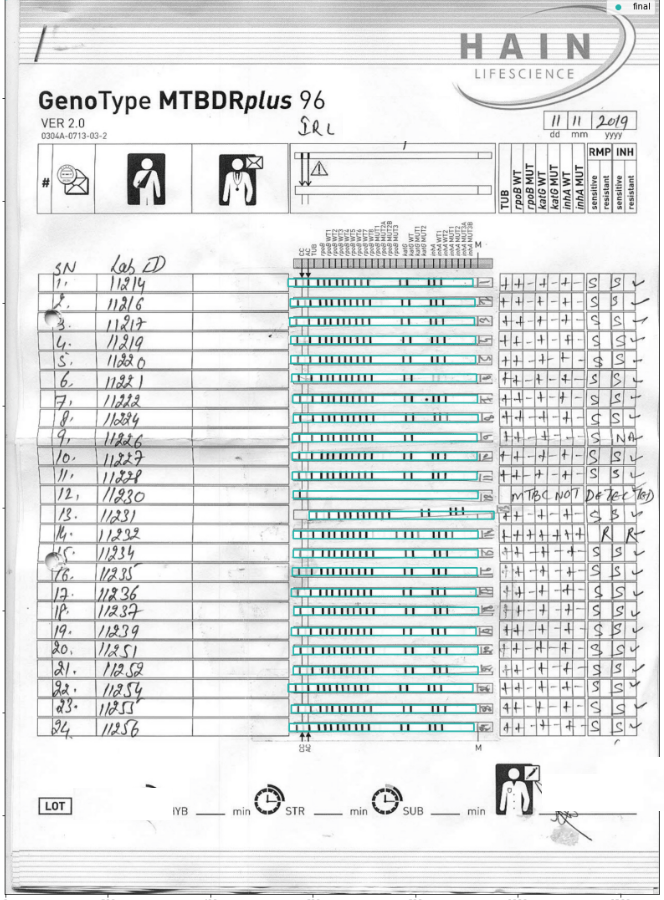
How does LPA work? It is a series of genetic markers laid out in a binary form. These genetic markers act like a barcode on a product you buy in the supermarket. The barcode identifies the product, its manufacturer, the date it was manufactured on, the batch number and when it expires. This genetic marker identifies the kind of TB the patient may have and what they could be sensitive to.
NTEP mandates that every confirmed pulmonary TB patient should be tested for drug sensitivity. This means that approximately 1.2 million newly diagnosed pulmonary TB patients should be tested for drug sensitivity testing. Currently, there are 61 culture and drug sensitivity test (CDST) laboratories that conduct the LPA test. And they manage to cover about 400,000 patients every year. There are plans to expand capabilities to service 1.2 million patients in the next two years.
Remember the importance of numbers? Here’s where it comes in. Once the genetic markers are recorded on that sheet above, it is interpreted to a form and then digitized and entered into a national database. All of this is a manual process, which involves several man-hours spent by lab technicians, microbiologists and data entry operators. Even if you consider just those who have been diagnosed with MDR-TB, the number baffles the mind.
And in manual processes, there is always scope for improving efficiency and avoiding potential errors. Any errors can cause great harm.
How can AI help?
We imagine a solution that can read these genetic markers, increasing efficiency and accuracy, and decreasing time for diagnosis. The time savings will also enable lab technicians as well as microbiologists to focus on more important tasks. Not only can the AI read the LPA but it can also populate the NIKSHAY database without too much trouble.
AI can be an elegant solution to this problem. But some solutions are best found in partnership. And that’s why we are seeking partners to come forward and help us forge a new path.